How to create AWS Glue Catalog
The AWS Glue Data Catalog is persistent technical metadata store in the AWS Cloud. Each AWS account has one AWS Glue Data Catalog per AWS Region. Each Data Catalog is a highly scalable collection of tables organized into databases.
In this tutorial we will create AWS Glue Data Catalog, which uses an Amazon S3 bucket as data source. We will be performing below three actions to create the AWS Glue Data Catalog.
- Create database
- Create table
- Use S3 bucket as a data source
1. Create database
1. Login to AWS console https://aws.amazon.com/console/ and search for Glue.
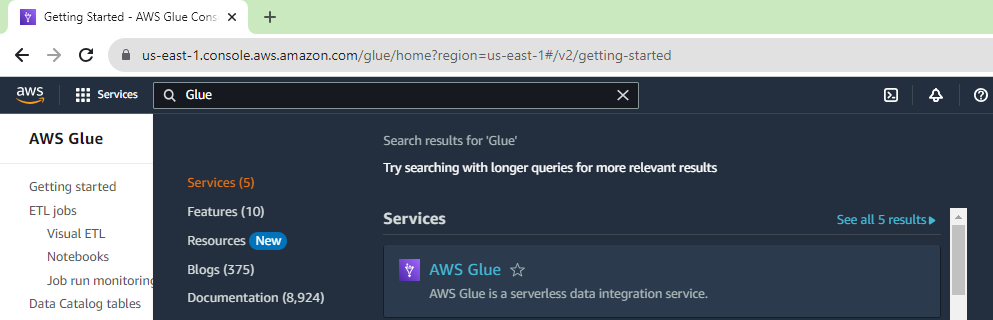
2. In the AWS Glue console, choose Databases under Data catalog.
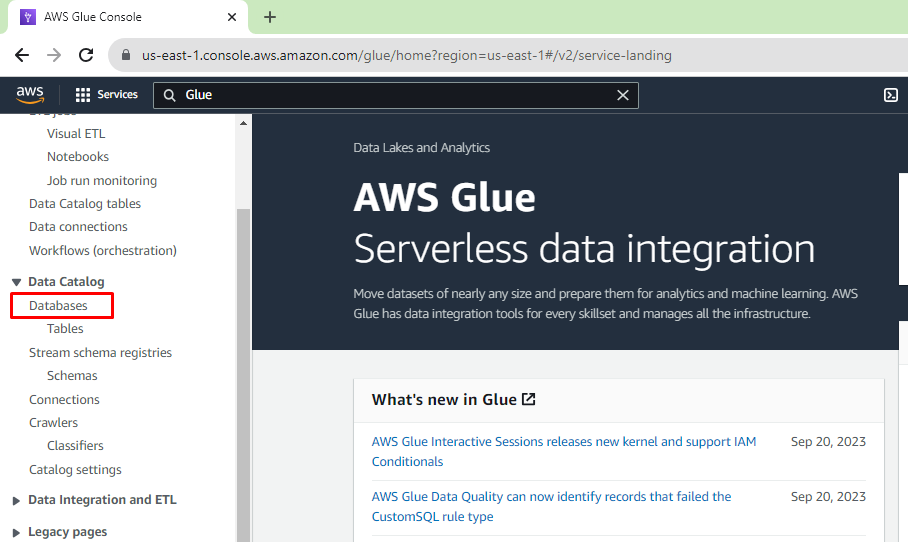
3. Click on Add database.
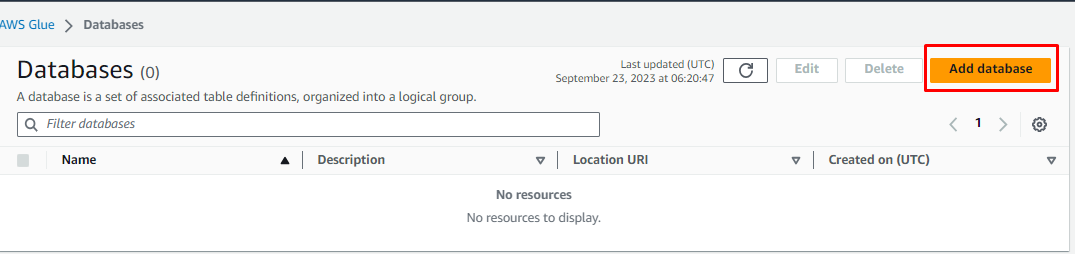
4. In the Create a database page enter Name ,Description for the database and click on Create database.

2. Create table
After creating the database lets create a table.
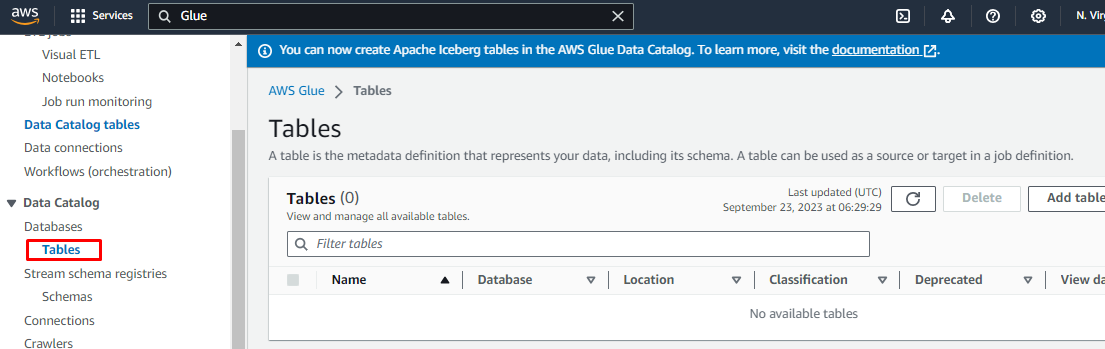
1. In the AWS Glue console, click on Tables.
2. Click on Add table.
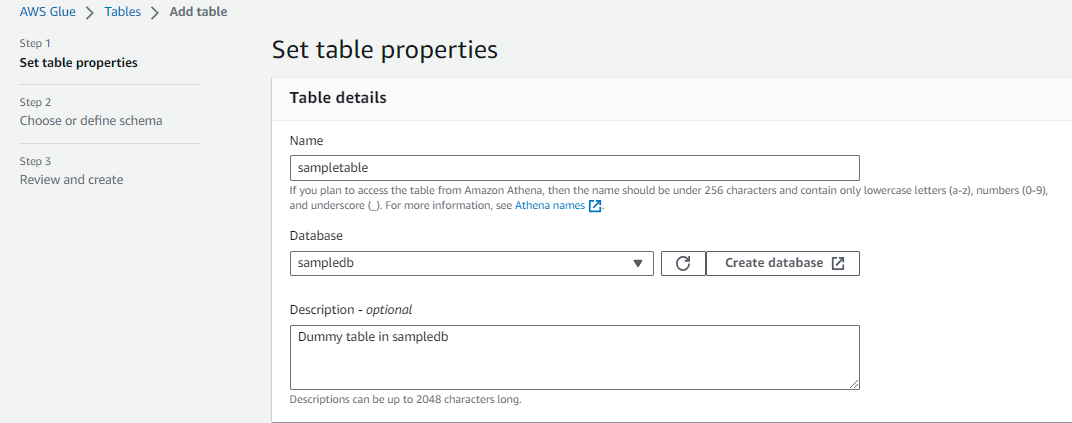
3. In the Set table properties page provide table Name, select the previously created database and enter description.
4. In the Table format select Standard AWS Glue table (default).
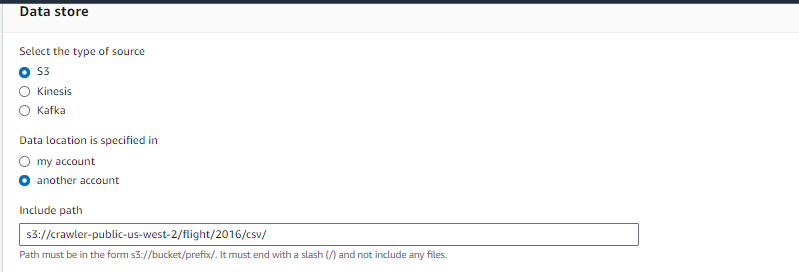
5. In the Data store for Select the type of source choose S3.
6. In the Data store for Data location is specified in choose Data location is specified in and paste s3://crawler-public-us-west-2/flight/2016/csv/ in input field.
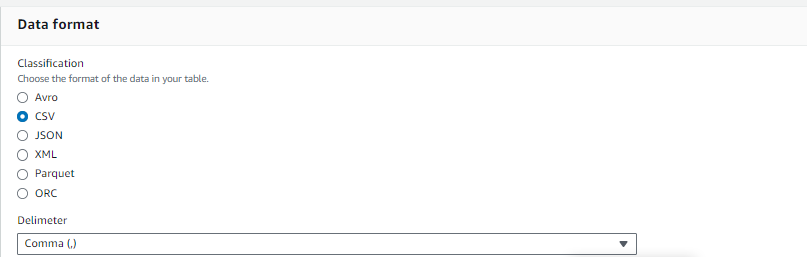
6. In the Data format for Classification, choose
CSV, for Delimiter, choose comma (,) and
click on Next.
7. For defining the schema click on Add column, specify the column property and click on Next.
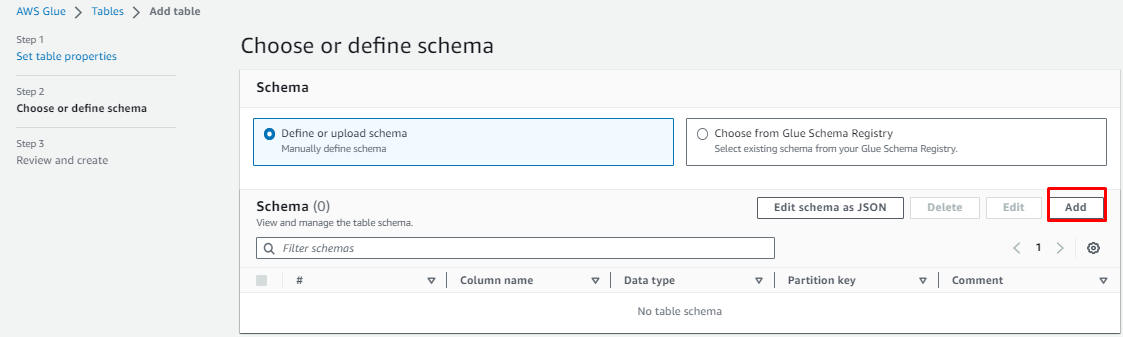
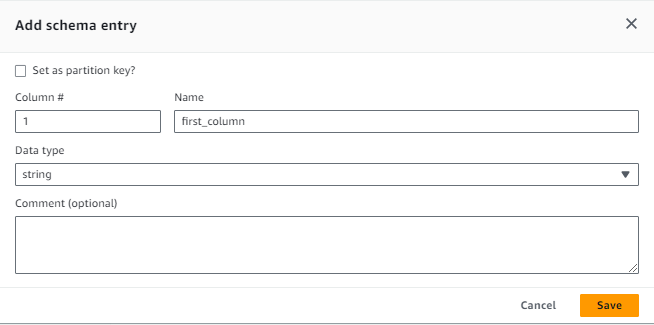
8. Review the table properties and if everything looks as good, click on Finish.
Category: AWS



