How to use pytesseract for non english languages
This post explains how to use Python pytesseract for
Non-English languages.
In order to follow this post tesseract needs to be installed in
system, refer below steps for tesseract installation, else skip to
download additional trained data.
Tesseract installation
1. Navigate to https://github.com/UB-Mannheim/tesseract/wiki and download Tesseract installer for Windows.
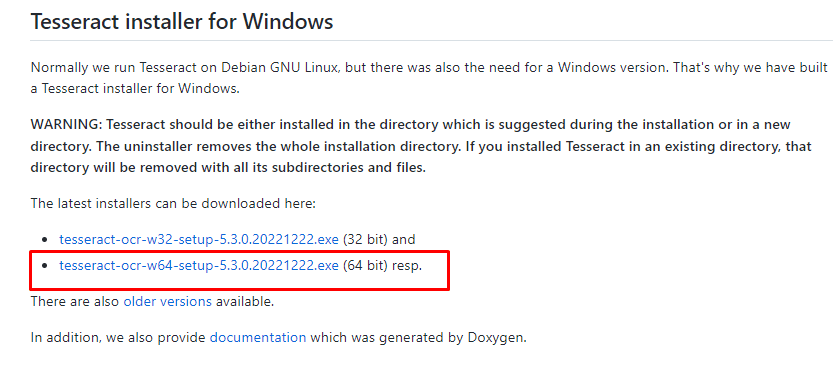
2. Double click on downloaded installer to begin the installation and select language.
3. Click on "Next" to continue installation.

4. In the "License Agreement" widget click on "I Agree".

5. In the "Choose Users" section select "Install for anyone using this computer".

6. In the "Choose Components" section click on "Next".
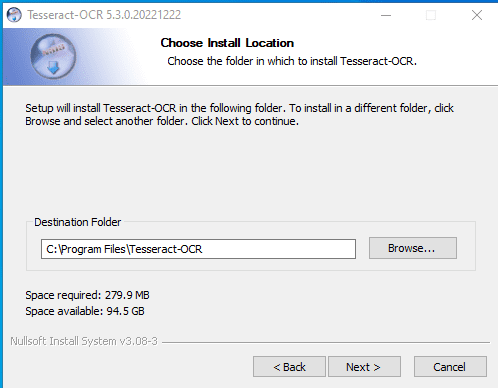
7. In the "Choose Install Location" section click on "Next".
7. In the "Choose Install Menu Folder" window click on "Install".
8. In the "Installation Complete" window click on "Next".
9. Click on "Finish" to complete the setup.
Non-English language ocr with pytesseract
Now the tesseract is installed, lets download the trained data for other languages. In this post we would be downloading trained data for "French" language, similar steps can be followed for other languages.
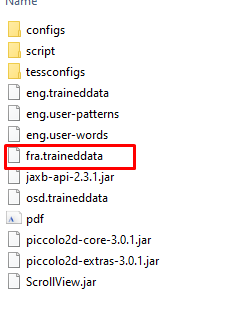
10. Navigate to https://github.com/tesseract-ocr/tessdata_best , click on "fra.traineddata" and click on "Download".


10. Copy the downloaded file in "C:\Program Files\Tesseract-OCR\tessdata".
If you have pytesseract installed than skip to
this, else refer below steps for
pytesseract installation.
1. Install pillow using pip.
pip install Pillow
2. Install pip pytesseract using pip.
pip install pytesseract
3. Create a Python file and write below code to list available supported languages.
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.get_languages(config=''))
Output
['eng', 'fra', 'osd']
From the above output we can see now "fra" is now included in list of available languages.
4. Write below code to extract "french" text from the images.
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.get_languages(config=''))
image_path = "test-french.png"
img = Image.open(image_path)
text = pytesseract.image_to_string(Image.open(image_path), lang='fra')
print(text)
5. Write below code to extract "french" text from the image and save to text file.
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.get_languages(config=''))
image_path = "test-french.png"
img = Image.open(image_path)
text = pytesseract.image_to_string(Image.open(image_path), lang='fra')
print(text)
with open("test.txt", "w", encoding="utf-8") as file:
file.writelines(text)
Category: Python



