How to Run DeepSeek-R1 Model Locally: Deploy AI on Your Laptop with Ollama & Python
DeepSeek-R1:1.5B – An Intro
If you're interested in AI models but don’t want to deal with the massive hardware requirements of bigger ones, DeepSeek-R1:1.5B might be just what you need. It’s a lightweight yet capable language model designed for tasks like text generation, summarization, and even coding help.
What Makes It Special?
- 1.5 Billion Parameters – A sweet spot between efficiency and performance.
- Fast & Lightweight – Runs smoothly on mid-range GPUs (even on CPUs) and doesn’t require high-end hardware.
- Versatile – Can generate text, answer questions, and assist in programming.
Why Should You Care?
Bigger AI models can be powerful, but they also need tons of computing power. DeepSeek-R1:1.5B is optimized to be fast, efficient, and easy to use, making it great for developers, researchers, or anyone curious about AI. Thinking of trying it out? Lets follow the below step by step guide to run the model on your laptop!
Prerequisites
- 8GB+ RAM (16GB recommended)
- Python 3.8+
- Ollama installed
Step 1: Install Ollama (Linux/macOS)
Download and set up the Ollama framework:
# For Linux/macOS
curl -fsSL https://ollama.com/install.sh | sh
Step 1: Install Ollama (Windows)
- Open a web browser in Windows.
- Go to Ollama's official website.
- Download the installation script for windows and run the script.
Explanation: Ollama provides optimized binaries for local LLM execution. Verify installation:
ollama --version
# Should output: ollama version 0.1.20 or higher
Step 2: Download DeepSeek-R1 Model
Pull the 1.5B parameter model:
ollama pull deepseek-r1:1.5bExplanation: This downloads the quantized version (∼900MB) optimized for local execution. Check available models:
ollama list
# Should show: deepseek-r1:1.5b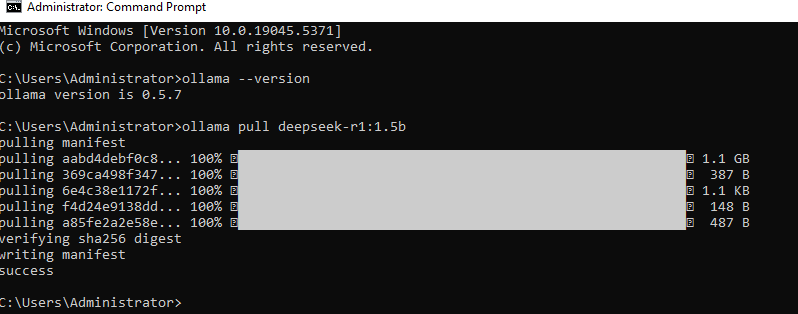
Step 3: Run the Model Locally
Start the model server:
ollama serveIf you are getting below error that means ollama is already running
listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address
(protocol/network address/port) is normally permitted.

In terminal, test basic interaction:
ollama run deepseek-r1:1.5b "Write a Python function to reverse a string"Explanation: The model will generate code directly on your machine without internet access.
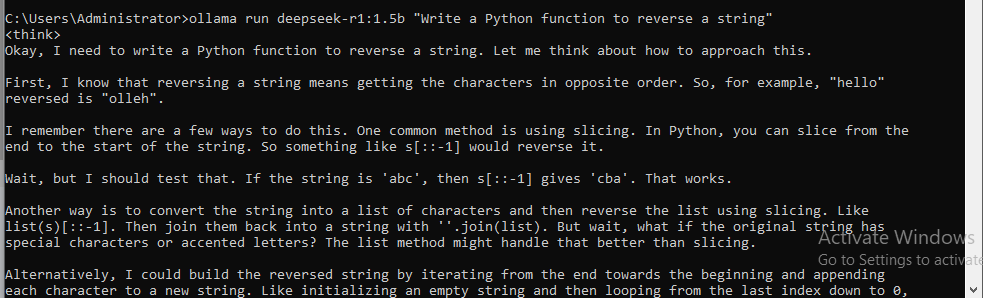
Step 4: Python Integration
Install the Python client:
pip install ollamaCreate a basic Python interface and save it in python file and run in terminal.
import ollama
response = ollama.generate(
model="deepseek-r1:1.5b",
prompt="Explain bubble sort in Python with example:"
)
print(response["response"])Explanation: The official Python client connects to the local Ollama server via port 11434.
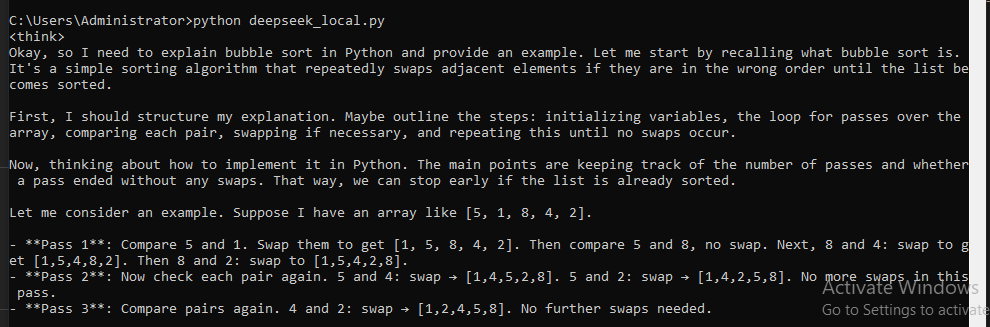
Step 5: Build a Simple AI Assistant
Create an interactive Python script: copy the below code in Python file and run it the terminal
import ollama
def ai_assistant():
print("DeepSeek-R1 Local Assistant (type 'exit' to quit)")
while True:
user_input = input("You: ")
if user_input.lower() == 'exit':
break
response = ollama.generate(
model="deepseek-r1:1.5b",
prompt=user_input
)
print(f"\nAssistant: {response['response']}\n")
if __name__ == "__main__":
ai_assistant()Explanation: This creates a ChatGPT-like interface running entirely on your laptop.
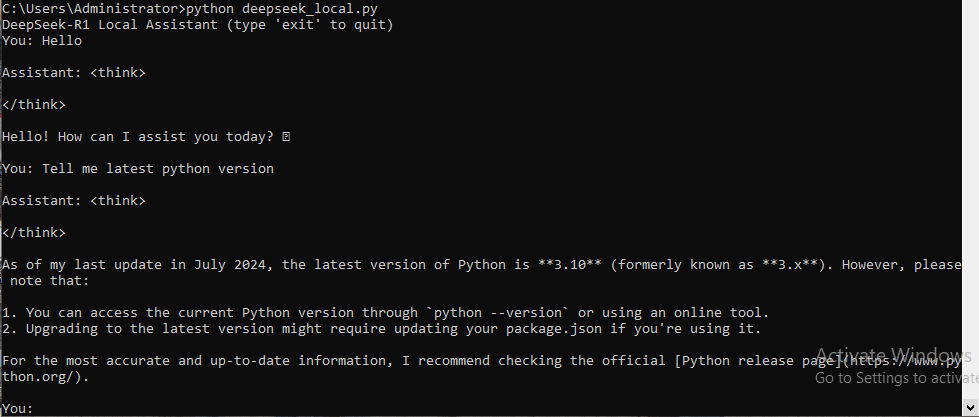
Step 6: Optimize Performance
Enable GPU acceleration (if available):
# Restart Ollama with GPU support
OLLAMA_GPU_LAYER=1 ollama serveAdjust memory usage:
# Limit VRAM usage (2GB example)
OLLAMA_VRAM_BUFFER=2048 ollama run deepseek-r1:1.5bExplanation: These environment variables help manage resource allocation on consumer hardware.
Step 7: Customize Model Behavior
Create a Modelfile for custom instructions:
FROM deepseek-r1:1.5b
SYSTEM """
You are a Python expert assistant. Always respond with:
1. Working code examples
2. Brief explanations
3. Time/space complexity analysis
"""Build and run your custom model:
ollama create my-py-expert -f Modelfile
ollama run my-py-expertStep 8: Batch Processing
Process multiple queries programmatically:
import ollama
queries = [
"Write a Python decorator for timing functions",
"Create a REST API endpoint in Flask",
"Explain recursion with a Fibonacci example"
]
for q in queries:
print(f"Processing: {q}")
response = ollama.generate(model="deepseek-r1:1.5b", prompt=q)
print(f"Response: {response['response'][:200]}...\n")Explanation: Automate code generation/documentation tasks using the local model.
Troubleshooting Tips
-
If you get "model not found", run
ollama pull deepseek-r1:1.5bagain - Use
ollama psto check running instances - Allocate more swap space if experiencing memory issues
Conclusion
You've now created a fully local AI development environment capable of handling Python tasks without cloud dependencies. Experiment with different prompts and consider integrating with your existing development workflow.
Category: deepseek


